Irrational Exuberance for 02/27/2019
Hi folks,
This is the weekly digest for my blog, Irrational Exuberance, and these are my posts from the last week. Always grateful to hear your thoughts and suggestions for topics to write about, drop me a tweet or direct message over on Twitter at @lethain.
Read posts on the blog:
-
Paying the predictability tax.
-
Valuing already-solved problems.
Paying the predictability tax.
{kind=link}
The core observations from Fred Brook's The Mythical Man Month is that assigning more folks to work on a project often slows delivery:
Men and months are interchangeable commodities only when a task can be partioned among many workers with no communication among them... when a task cannot be partitioned because of sequential constraints, the application of more effort has no effect on the schedule.
As I've been rethinking our approach to planning, one particularly interesting aspect of Brooks' communication cost is that larger teams require the prioritization of predictability over throughput.
While in the best case, good architecture will minimize dependencies, it's neither possible nor advisable to eliminate all dependencies, because all leveraged work creates dependencies, and you do want to be doing leveraged work to run a productive organzation.
The more teams involved in creating a plan, the more conservative you have to be with each component's delivery dates, to minimize uncertainty introduced in the overall timeline. One team self-coordinating can take advantage of all of their productivity, e.g. operate at "p100" productivity. If there are two teams with heavy cross-dependencies and somewhat flexible timelines, then perhaps you can operate at "p80 productivity."
As you add more and more teams, you quickly reach a place where predictability means you can rely on your "p50 productivity" at best.
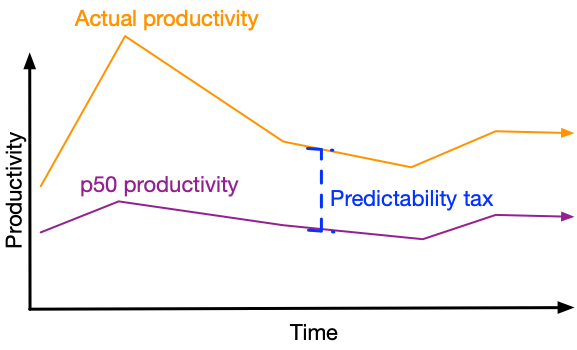
The difference between your team's actual productivity and the productivity it's able to demonstrate with required predictability is your team's predictabilty tax.
While this predictability tax manifests in many ways, one good example of how emphasizing predictability shifts behavior is team planning process:
- Kanban focuses exclusively on maximizing throughput, with work-in-progress limits generating back pressure to drive a cycle of virtuous team/process/system improvement.
- Agile focuses on focuses several week sprints, and adapts to new information rapidly at the end of each sprint.
- Waterfall focuses on defining the end state and then reasoning backwards to identify the necessary milestones to reach that target.
Almost no company acknowledges using a waterfall-style planning methodology, but almost every company approaches cross-team planning with a waterfall-based mental model of commitments and coordination in order to hit their predictability requirements.
This means they spend less time optimizng their approach to delivery or optimizing their product decisions, with that potential energy shifting to optimizing timelines.
There's no quick fix for coordination. Your four best tools are good technical architecture, good organizational design, good process design, and remembering to pay attention.
Valuing already-solved problems.
Product market fit for business-to-business products hinges on when your customer first encounters the problem you solve. If you're selling to a company that is newly encountering the problem, then you get to sell them on your product's value. However, a mature company likely already has a working solution, and you're stuck selling on reduced total cost of ownership, a much harder sale.
This can make it difficult to determine if you have fit for larger customers: you can't validate against existing large businesses. Instead, you have to wait for early stage companies who adopted your product to solve their initial problem to become large companies.
This dynamic ends up shaping most business to business products, here are a few examples.
Metrics and dashboards
For a long time, companies that wanted to create metric dashboards had few options. Most ended up using Graphite or (slightly later) Grafana. These are complex systems to operate, and an IaaS ecosystem has emerged featuring Datadog and SignalFx.
Many new companies default to using one of those IaaS vendors, They need metric dashboards and don't want to invest engineering time into provisioning, maintaining and scaling Graphite, so it's an easy value proposition.
On the other hand, older companies have already built competencies around running Graphite or have developed their own solution like Uber's M3. To consider shifting off, they have to make a believable case that this is a cheaper way to maintain the existing tooling's value, including the opportunity cost of migrating to the new system.
Most can't.
Request tracing
Anyone who's read Google's Dapper paper has dreamied of request tracing for the past decade. This has culminated in a rich opensource ecosystem featuring OpenTracing and Jaeger, as well as commercial attempts such as AWS X-Ray and LightStep.
However, fairly few existing companies that have succeeded in incorporating these tools into their debugging workflows. Instead, they already have homegrown solutions, which may not be elegant–filtering logs in ELK or Splunk by a request id passed through the request stack–but work well enough and don't require their engineers learn a new tool.
Modern real-time request tracing differentiates from log-based solutions by storing traces in memory. Storing raw events in memory supports high-cardinality metrics with higher cost efficiency than metrics-based approaches that depend on pre-compiling data points. This is a novel capability, but it often makes these solutions have a higher total cost of ownership than companies' existing log based solutions.
Mature companies have typically already solved these needs and the cost model makes it difficult for request tracing products to compete on the basis of total cost, which makes it unlikely that in-memory request tracing will ever penetrate today's large companies, and also puts it at risk for fit with tomorrow's large companies as well.
One potential exception is around companies moving to service oriented architectures, where debugging cross-services creates an opportunity for request tracing to be value-creating, even in a mature technology companies.
Applicant tracking systems
Applicant Tracking Systems (ATS) are a good non-infrastructure example of the same phenomenon. Many newer companies adopt Greenhouse or Lever for their ATS to good result. However, many older companies continue to use an internally created ATS, some of which are quite advanced and specialized to their needs (e.g. Google), but many of which–on closer inspection–turn out to be unversioned spreadsheets shared over email.
Most companies in the later category would benefit from moving to a modern ATS, often struggling to hire recruiters who want to work with effective tools, but because they've already solved the problem they can only value the offering on cost-savings, not on capabilities.
They typically end up not switching.
There are a bunch of other examples that we could go into:
- Slack's early struggles to displace companies that had already adopted Hipchat, or even private IRC servers, that culminated somewhat surprisingly in Slack's eventual acquisition of Hipchat.
- Adoption of ELK versus Splunk at various company sizes and ages.
They mostly retread the same patterns, so I won't expand on them, but each of them is quite interesting in the particulars.
Summarizing: how companies value your product depends more on their lifecycle than on your product. Just because you can’t sell into large users today doesn’t necessarily mean that you don’t have product market fit for tomorrow's large users. If you engage them early, you may very well be able to serve them well as they become a large user.
You shouldn't assume you do have fit. You just don't know either way.
That's all for now! Hope to hear your thoughts on Twitter at @lethain!
|