Is this strategy any good? @ Irrational Exuberance
Hi folks,
This is the weekly digest for my blog, Irrational Exuberance. Reach out with thoughts on Twitter at @lethain, or reply to this email.
Posts from this week:
-
Is this strategy any good?
-
Steps to build an engineering strategy.
Is this strategy any good?
We’ve read a lot of strategy at this point in the book. We can judge a strategy’s format, and its construction: both are useful things. However, format is a predictor of quality, not quality itself. The remaining question is, how should we assess whether a strategy is any good?
Uber’s service migration strategy unlocked the entire organization to make rapid progress. It also led to a sprawling architecture problem down the line. Was it a great strategy or a terrible one? Folks can reasonably disagree, but it’s worthwhile developing our point of view why we should prefer one interpretation or the other.
This chapter will focus on:
- The various ways that are frequently suggested for evaluating strategies, such as input-only evaluation, output-only evaluation, and so on
- A rubric for evaluating strategies, and why a useful rubric has to recognize that strategies have to be evaluated in phases rather than as a unified construct
- Why ending a strategy is often a sign of a good strategist, and sometimes the natural reaction to a new phase in a strategy, rather than a judgment on prior phases
- How missing context is an unpierceable veil for evaluating other companies' strategies with high-conviction, and why you’ll end up attempting to evaluate them anyway
- Why you can learn just as much from bad strategies as from good ones, even in circumstances where you are missing much of the underlying context
Time to refine our judgment about strategy quality a bit.
This is an exploratory, draft chapter for a book on engineering strategy that I’m brainstorming in #eng-strategy-book. As such, some of the links go to other draft chapters, both published drafts and very early, unpublished drafts.
How are strategies graded?
Before suggesting my own rubric, I want to explore how the industry appears to grade strategies in practice. That’s not because I particularly agree with them–I generally find each approach is missing an important nuance–understanding their flaws is a foundation to build on.
Grading strategy on its outputs is by far the most prevalent approach I’ve found in industry. This is an appealing approach, because it does make sense that a strategy’s results are more important than anything else. However, this line of thinking can go awry. We saw massive companies like Google move to service architectures, and we copied them because if it worked for Google, it would likely work for us. As discussed in the monolith decomposition strategy, it did not work particularly well for most adopters.
The challenge with grading outputs is that it doesn’t distinguish between “alpha”, how much better your results are because of your strategy, and “beta”, the expected outcome if you hadn’t used the strategy. For example, the acquisition of Index allowed Stripe to build a point-of-sale business line, but they were also on track to internally build that business. Looking only at outputs can’t distinguish whether it would have been better to build the business via acquisition or internally. But one of those paths must have been the better strategy.
Similarly, there are also strategies that succeed, but do so at unreasonably high costs. Stripe’s API deprecation strategy is a good example of a strategy that was extremely well worth the cost for the company’s first decade, but eventually became too expensive to maintain as the evolving regulatory environment created more overhead. Fortunately, Stripe modified their strategy to allow some deprecations, but you can imagine an alternate scenario where they attempted to maintain their original strategy, which would have likely failed due to its accumulating costs.
Confronting these problems with judging on outputs, it’s compelling to switch to the opposite lens and evaluate strategy purely on its inputs. In that approach, as long as the sum of the strategy’s parts make sense, it’s a good strategy, even if it didn’t accomplish its goals. This approach is very appealing, because it appears to focus purely on the strategy’s alpha.
Unfortunately I find this view similarly deficient. For example, the strategy for adopting LLMs offers a cautious approach to adopting LLMs. If that company is outcompeted by competitors in the incorporation of LLMs, to the loss of significant revenue, I would argue that strategy isn’t a great one, even if it’s rooted in a proper diagnosis and effective policies. Doing good strategy requires reconciling the theoretical with the practical, so we can’t argue that inputs alone are enough to evaluate strategy work. If a strategy is conceptually sound, but struggling to make an impact, then its authors should continue to refine it. If its authors take a single pass and ignore subsequent information that it’s not working, then it’s a failed strategy, regardless of how thoughtful the first pass was.
While I find these mechanisms to be incomplete, they’re still instructive. By incorporating bits of each of these observations, we’re surprisingly close to a rubric that avoids each of these particular downfalls.
Rubric for strategy
Balancing the strengths and flaws of the previous section’s ideas, the rubric I’ve found effective for evaluating strategy is:
- How quickly is the strategy refined? If a strategy starts out bad, but improves quickly, that’s a better strategy than a mostly right strategy that never evolves. Strategy thrives when its practitioners understand it is a living endeavour.
- How expensive is the strategy’s refinement for implementing and impacted teams? Just as culture eats strategy for breakfast, good policy loses to poor operational mechanisms every time. Especially early on, good strategy is validated cheaply. Expensive strategies are discarded before they can be validated, let alone improved.
- How well does the current iteration solve its diagnosis? Ultimately, strategy does have to address the diagnosis it starts from. Even if you’re learning quickly and at a low cost, at some point you do have to actually get to impact. Strategy must eventually be graded on its impact.
With this rubric in hand, we can finally assess the Uber’s service migration strategy. It refined rapidly as we improved our tooling, minimized costs because we had to rely on voluntary adoption, and solved its diagnosis extremely well. So this was a great strategy, but how do we think about the fact that its diagnosis missed out on the consequences of a wide-spread service architecture on developer productivity?
This brings me to the final component of the strategy quality rubric: the recognition that strategy exists across multiple phases. Each phase is defined by new information–whether or not this information is known by the strategy’s authors–that render the diagnosis incomplete.
The Uber strategy can be thought of as existing across two phases:
- Phase 1 used service provisioning to address developer productivity challenges in the monolith.
- Phase 2 was engaging with consequences of a sprawling service architecture.
All the good grades I gave the strategy are appropriate to the first phase. However, the second phase was ushered in by the negative impacts to developer productivity exposed by the initial rollout. The second phase’s grades on the rate of iteration, the cost, and the outcomes were reasonable, but a bit lower than first phase. In the subsequent years, the second phase was succeeded by a third phase that aimed to address the second’s challenges.
Does stopping mean a strategy’s bad?
Now that we have a rubric, we can use it to evaluate one of the important questions of strategy: does giving up on a strategy mean that the strategy is a bad one?
The vocabulary of strategy phases helps us here, and I think it’s uncontroversial to say that a new phase’s evolution of your prior diagnosis might make it appropriate to abandon a strategy. For example, Digg owned our own servers in 2010, but would certainly not buy their own servers if they started ten years later. Circumstances change.
Sometimes I also think that aborting a strategy in its first phase is a good sign. That’s generally true when the rate of learning is outpaced by the cost of learning. I recently sponsored a developer productivity strategy that had some impact, but less than we’d intended. We immortalized a few of the smaller pieces, and returned further exploration to a lower altitude strategy owned by the teams rather than the high altitude strategy that I owned as an executive.
Essentially all strategies are competing with strategies at other altitudes, so I think giving up on strategies, especially high altitude strategies, is almost always a good idea.
The unpierceable veil
Working within our industry, we are often called upon to evaluate strategies from afar. As other companies rolled out LLMs in their products or microservices for their architectures, our companies pushed us on why we weren’t making these changes as well. The exploration step of strategy helps determine where a strategy might be useful for you, but even that doesn’t really help you evaluate whether the strategy or the strategists.
There are simply too many dimensions of the rubric that you cannot evaluate when you’re far away. For example, how many phases occurred before the idea that became the external representation of the strategy came into existence? How much did those early stages cost to implement? Is the real mastery in the operational mechanisms that are never reported on? Did the external representation of the strategy ever happen at all, or is it the logical next phase that solves the reality of the internal implementation?
With all that in mind, I find that it’s generally impossible to accurately evaluate strategies happening in other companies with much conviction. Even if you want to, the missing context is an impenetrable veil. That’s not to say that you shouldn’t try to evaluate their strategies, that’s something that you’ll be forced to do in your own strategy work. Instead, it’s a reminder to keep a low confidence score in those appraisals: you’re guaranteed to be missing something.
Learning despite quality issues
Although I believe it’s quite valuable for us to judge the quality of strategies, I want to caution against going a step further and making the conclusion that you can’t learn from poor strategies. As long as you are aware of a strategy’s quality, I believe you can learn just as much from failed strategies as from great strategy.
Part of this is because often even failed strategies have early phases that work extremely well. Another part is because strategies tend to fail for interesting reasons. I learned just as much from Stripe’s failed rollout of agile, which struggled due to missing operational mechanisms, as I did from Calm’s successful transition to focus primarily on product engineering. Without a clear point of view on which of these worked, you’d be at risk of learning the wrong lessons, but with forewarning you don’t run that risk.
Once you’ve determined a strategy was unsuccessful, I find it particularly valuable to determine the strategy’s phases and understand which phase and where in the strategy steps things went wrong. Was it a lack of operational mechanisms? Was the policy itself a poor match for the diagnosis? Was the diagnosis willfully ignoring a truculent executive? Answering these questions will teach you more about strategy than only studying successful strategies, because you’ll develop an intuition for which parts truly matter.
Summary
Finishing this chapter, you now have a structured rubric for evaluating a strategy, moving beyond “good strategy” and “bad strategy” to a nuanced assessment. This assessment is not just useful for grading strategy, but makes it possible to specifically improve your strategy work.
Maybe your approach is sound, but your operational mechanisms are too costly for the rate of learning they facilitate. Maybe you’ve treated strategy as a single iteration exercise, rather than recognizing that even excellent strategy goes stale over time. Keep those ideas in mind as we head into the final chapter on how you personally can get better at strategy work.
Steps to build an engineering strategy.
Often you’ll see a disorganized collection of ideas labeled as a “strategy.” Even when they’re dense with ideas, these can be hard to parse, and are a major reason why most engineers will claim their company doesn’t have a clear strategy even though my experience is that all companies follow some strategy, even if it’s undocumented.
This chapter lays out a repeatable, structured approach to drafting strategy. It introduces each step of that approach, which are then detailed further in their respective chapters. Here we’ll cover:
- How these five steps fit together to facilitate creating strategy, especially by preventing practitioners from skipping steps that feel awkward or challenging.
- Step 1: Exploring the wider industry’s ideas and practices around the strategy you’re working on. Exploration is understanding what recent research might change your approach, and how the state of the art has changed since you last tackled a similar problem.
- Step 2: Diagnosing the details of your problem. It’s hard to slow down to understand your problem clearly before attempting to solve it, but it’s even more difficult to solve anything well without a clear diagnosis.
- Step 3: Refinement is taking a raw, unproven set of ideas and testing them against reality. Three techniques are introduced to support this validation process: strategy testing, systems modeling, and Wardley mapping.
- Step 4: Policy makes the tradeoffs and decisions to solve your diagnosis. These can range from specifying how software is architected, to how pull requests are reviewed, to how headcount is allocated within an organization.
- Step 5: Operations are the concrete mechanisms that translate policy into an active force within your organization. These can be nudges that remind you about code changes without associated tests, or weekly meetings where you study progress on a migration.
- Whether these steps are sacred or are open to adaptation and experimentation, including when you personally should persevere in attempting steps that don’t feel effective.
From this chapter’s launching point, you’ll have the high-level summaries of each step in strategy creation, and can decide where you want to read further.
This is an exploratory, draft chapter for a book on engineering strategy that I’m brainstorming in #eng-strategy-book. As such, some of the links go to other draft chapters, both published drafts and very early, unpublished drafts.
How the steps become strategy
Creating effective strategy is not rote incantation of a formula. You can’t merely follow these steps to guarantee that you’ll create a great strategy. However, I’ve found over and over is that strategies fail more due to avoidable errors than from fundamentally unsound thinking. Busy people skip steps. Especially steps they dislike or have failed at before.
These steps are the scaffolding to avoid those errors. By practicing routinely, you’ll build powerful habits and intuition around which approach is most appropriate for the current strategy you’re working on. They also help turn strategy into a community practice that you, your colleagues, and the wider engineering ecosystem can participate in together.
Each step is an input that flows into the next step. Your exploration is the foundation of a solid diagnosis. Your diagnosis helps you search the infinite space of policy for what you need now. Operational mechanisms help you turn policy into an active force supporting your strategy rather than an abstract treatise.
If you’re skeptical of the steps, you should certainly maintain your skepticism, but do give them a few tries before discarding them entirely. You may also appreciate the discussion in the chapter on bridging between theory and practice when doing strategy.
Explore
Exploration is the deliberate practice of searching through a strategy’s problem and solution spaces before allowing yourself to commit to a given approach. It’s understanding how other companies and teams have approached similar questions, and whether their approaches might also work well for you. It’s also learning why what brought you so much success at your former employer isn’t necessarily the best solution for your current organization.
The Uber service migration strategy used exploration to understand the service ecosystem by reading industry literature:
As a starting point, we find it valuable to read Large-scale cluster management at Google with Borg which informed some elements of the approach to Kubernetes, and Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center which describes the Mesos/Aurora approach.
It also used a Wardley map to explore the cloud compute ecosystem.
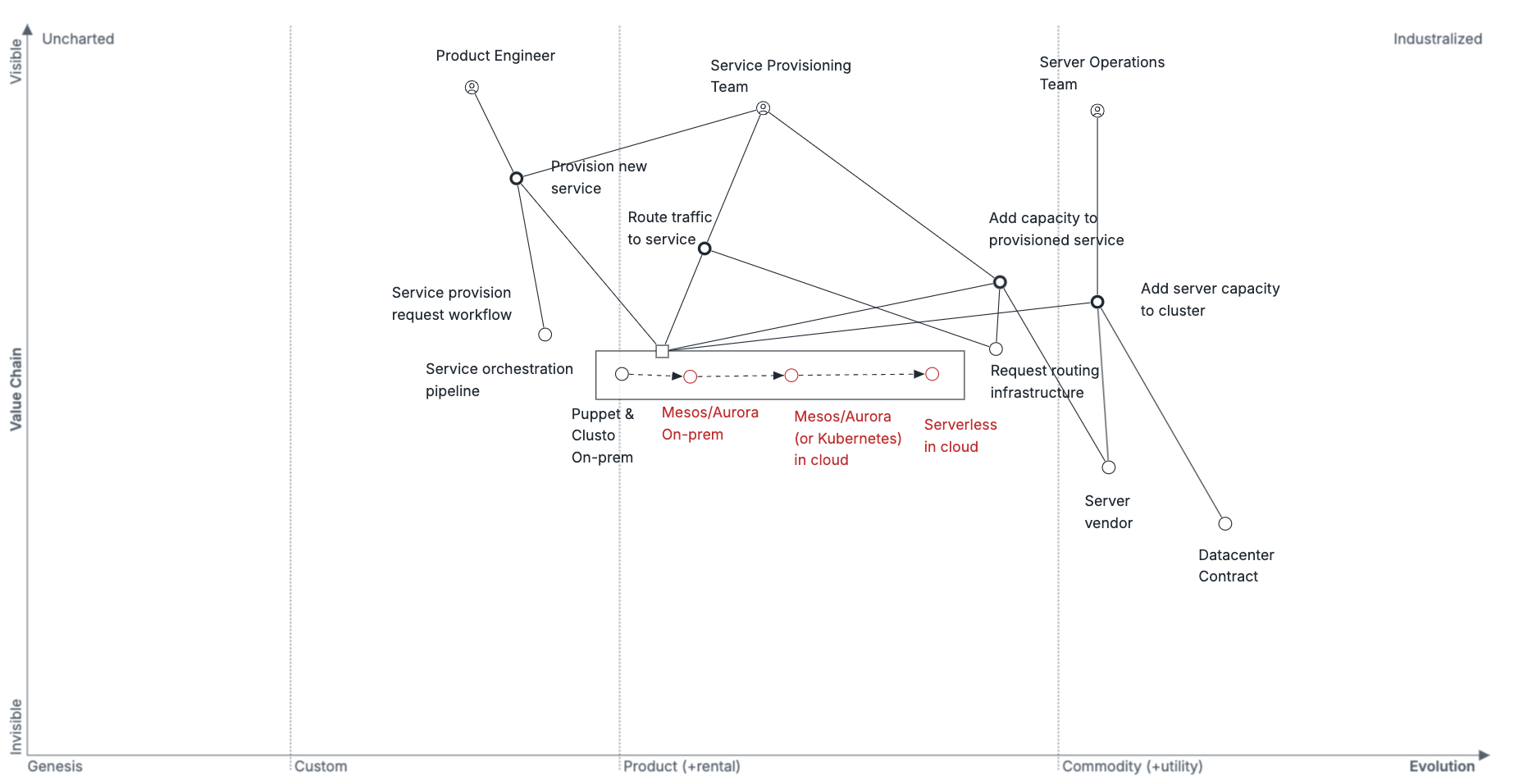
For more detail, read the Exploration chapter.
Diagnose
Diagnosis is your attempt to correctly recognize the context that the strategy needs to solve before deciding on the policies to address that context. Starting from your exploration’s learnings, and your understanding of your current circumstances, building a diagnosis forces you to delay thinking about solutions until you fully understand your problem’s nuances.
A diagnosis can be largely data driven, such as the navigating a Private Equity ownership transition strategy:
Our Engineering headcount costs have grown by 15% YoY this year, and 18% YoY the prior year. Headcount grew 7% and 9% respectively, with the difference between headcount and headcount costs explained by salary band adjustments (4%), a focus on hiring senior roles (3%), and increased hiring in higher cost geographic regions (1%).
It can also be less data driven, instead aiming to summarize a problem, such as the Index acquisition strategy’s summary of the known and unknown elements of the technical integration prior to the acquisition closing:
We will need to rapidly integrate the acquired startup to meet this timeline. We only know a small number of details about what this will entail. We do know that point-of-sale devices directly operate on payment details (e.g. the point-of-sale device knows the credit card details of the card it reads).
Our compliance obligations restrict such activity to our “tokenization environment”, a highly secured and isolated environment with direct access to payment details. This environment converts payment details into a unique token that other environments can utilize to operate against payment details without the compliance overhead of having direct access to the underlying payment details.
The approach, and challenges, of developing a diagnosis are detailed in the Diagnosis chapter.
Refine (Test, Map & Model)
Strategy refinement is a toolkit of methods to identify which parts of your diagnosis are most important, and verify that your approach to solving the diagnosis actually works. This chapter delves into the details of using three methods in particular: strategy testing, systems modeling, and Wardley mapping.
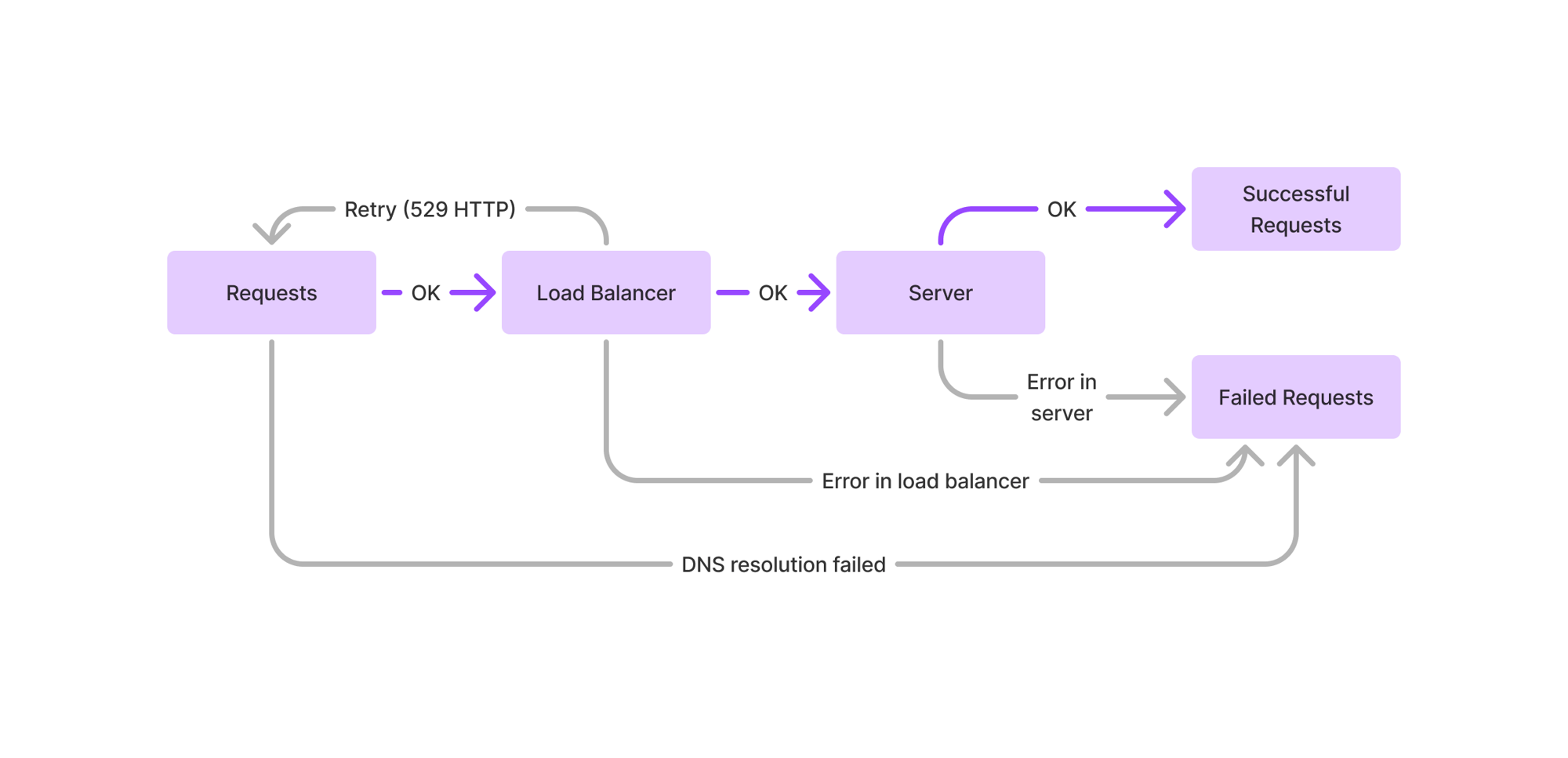
An example of a systems modeling diagram.
These techniques are also demonstrated in the strategy case studies, such as the Wardley map of the LLM ecosystem, or the systems model of backfilling roles without downleveling them.
For more detail, read the Refinement chapter.
Why isn’t refinement earlier (or later)?
A frequent point of disagreement is that refinement should occur before the diagnosis. Another is that mapping and modeling are two distinct steps, and mapping should occur before diagnosis, and modeling should occur after policy. A third is that refinement ought to be the final step of strategy, turning the steps into a looping cycle. These are all reasonable observations, so let me unpack my rationale for this structure.
By far the biggest risk for most strategies is not that you model too early or map too late, but instead that you simply skip both steps entirely. My foremost concern is minimizing the required investment into mapping and modeling such that more folks do these steps at all. Refining after exploring and diagnosing allows you to concentrate your efforts on a smaller number of load-bearing areas.
That said, it’s common to refine many places in your strategy creation. You’re just as likely to have three small refinement steps as one bigger one.
Policy
Policy is interpreting your diagnosis into a concrete plan. This plan also needs to work, which requires careful study of what’s worked within your company, and what new ideas you’ve discovered while exploring the current problem.
Policies can range from providing directional guidance, such as the user data controls strategy’s guidance:
Good security discussions don’t frame decisions as a compromise between security and usability. We will pursue multi-dimensional tradeoffs to simultaneously improve security and efficiency. Whenever we frame a discussion on trading off between security and utility, it’s a sign that we are having the wrong discussion, and that we should rethink our approach.
We will prioritize mechanisms that can both automatically authorize and automatically document the rationale for accesses to customer data. The most obvious example of this is automatically granting access to a customer support agent for users who have an open support ticket assigned to that agent. (And removing that access when that ticket is reassigned or resolved.)
To committing not to make a decision until later, as practiced in the Index acquisition strategy:
Defer making a decision regarding the introduction of Java to a later date: the introduction of Java is incompatible with our existing engineering strategy, but at this point we’ve also been unable to align stakeholders on how to address this decision. Further, we see attempting to address this issue as a distraction from our timely goal of launching a joint product within six months.
We will take up this discussion after launching the initial release.
This chapter further goes into evaluating policies, overcoming ambiguous circumstances that make it difficult to decide on an approach, and developing novel policies.
For full detail, read the Policy chapter.
Operations
Even the best policies have to be interpreted. There will be new circumstances their authors never imagined, and the policies may be in effect long after their authors have left the organization. Operational mechanisms are the concrete implementation of your policy.
The simplest mechanisms are an explicit escalation path, as shown in Calm’s product engineering strategy:
Exceptions are granted by the CTO, and must be in writing. The above policies are deliberately restrictive. Sometimes they may be wrong, and we will make exceptions to them. However, each exception should be deliberate and grounded in concrete problems we are aligned both on solving and how we solve them. If we all scatter towards our preferred solution, then we’ll create negative leverage for Calm rather than serving as the engine that advances our product.
From that starting point, the mechanisms can get far more complex. This chapter works through evaluating mechanisms, composing an operational plan, and the most common sorts of operational mechanisms that I’ve seen across strategies.
For more detail, read the Operations chapter.
Is the structure sacrosanct?
When someone’s struggling to write a strategy document, one of the first tools someone will often recommend is a strategy template. Templates are great: they reduce the ambiguity of an already broad project into something more tractable. If you’re wondering if you should use a template to craft strategy: sure, go ahead!
However, I find that well-meaning, thoughtful templates often turn into lumbering, callous documents that serve no one well. The secret to good templates is that someone has to own it, and that person has to care about the template writer first and foremost, rather than the various constituencies that want to insert requirements into the strategy creation process. The security, compliance and cost of your plans matter a lot, but many organizations start to layer in more and more requirements into these sorts of documents until the idea of writing them becomes prohibitively painful.
The best advice I can give someone attempting to write strategy, is that you should discard every element of strategy that gets in your way as long as you can explain what that element was intended to accomplish. For example, if you’re drafting a strategy and you don’t find any operational mechanisms that fit. That’s fine, discard that section. Ultimately, the structure is not sacrosanct, it’s the thinking behind the sections that really matter.
This topic is explored in more detail in the chapter on Making engineering strategies more readable.
Summary
Now, you know the foundational steps to conducting strategy. From here, you can dive into the details with the strategy case studies like How should you adopt LLMs? or you can maintain a high altitude starting with how exploration creates the foundation for an effective strategy.
Whichever you start with, I encourage you to eventually work through both to get the full perspective.
That's all for now! Hope to hear your thoughts on Twitter at @lethain!
|