library-mcp: working with Markdown knowledge bases @ Irrational Exuberance
Hi folks,
This is the weekly digest for my blog, Irrational Exuberance. Reach out with thoughts on Twitter at @lethain, or reply to this email.
Posts from this week:
-
library-mcp: working with Markdown knowledge bases
-
Refreshed StaffEng.com and a few other sites
-
Why did Stripe build Sorbet? (~2017).
library-mcp: working with Markdown knowledge bases
At work, we’ve been building agentic workflows to support our internal Delivery team on various accounting, cash reconciliation, and operational tasks. To better guide that project, I wrote my own simple workflow tool as a learning project in January. Since then, the Model Context Protocol (MCP) has become a prominent solution for writing tools for agents, and I decided to spend some time writing an MCP server over the weekend to build a better intuition.
The output of that project is library-mcp,
a simple MCP that you can use locally with tools like Claude Desktop
to explore Markdown knowledge bases.
I’m increasingly enamored with the idea of “datapacks” that I load into context windows with relevant
work, and I am currently working to release my upcoming book in a “datapack” format that’s optimized for usage with LLMs.
library-mcp allows any author to dynamically build datapacks relevant to their current question,
as long as they have access to their content in Markdown files.
A few screenshots tell the story. First, here’s a list of the tools provided by this server. These tools give a variety of ways to search through content and pull that content into your context window.
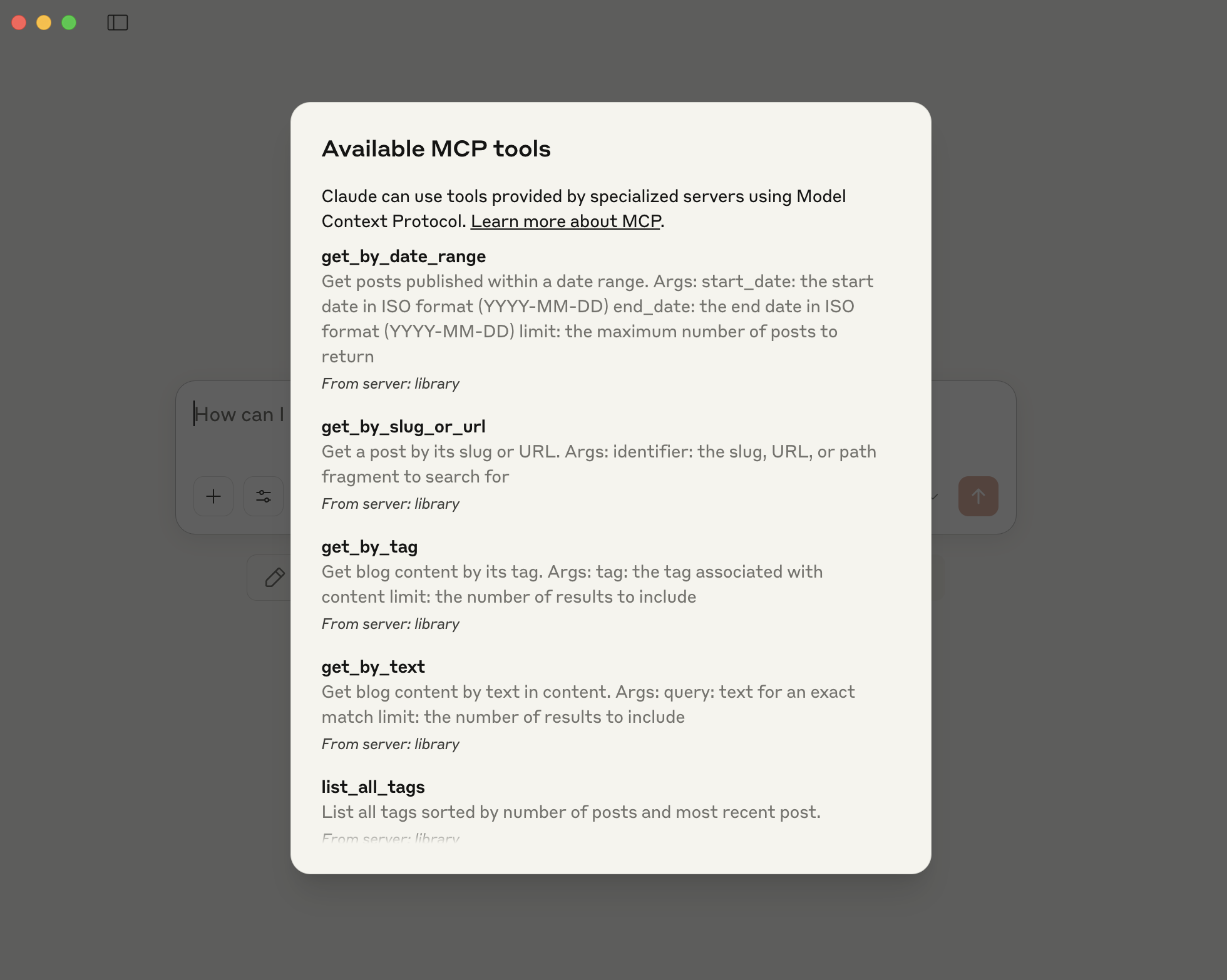
Each time you access a tool for the first time in a chat, Claude Desktop prompts you to verify you want that tool to operate. This is a nice feature, and I think it’s particularly important that approval is done at the application layer, not at the agent layer. If agents approve their own usage, well, security is going to be quite a mess.
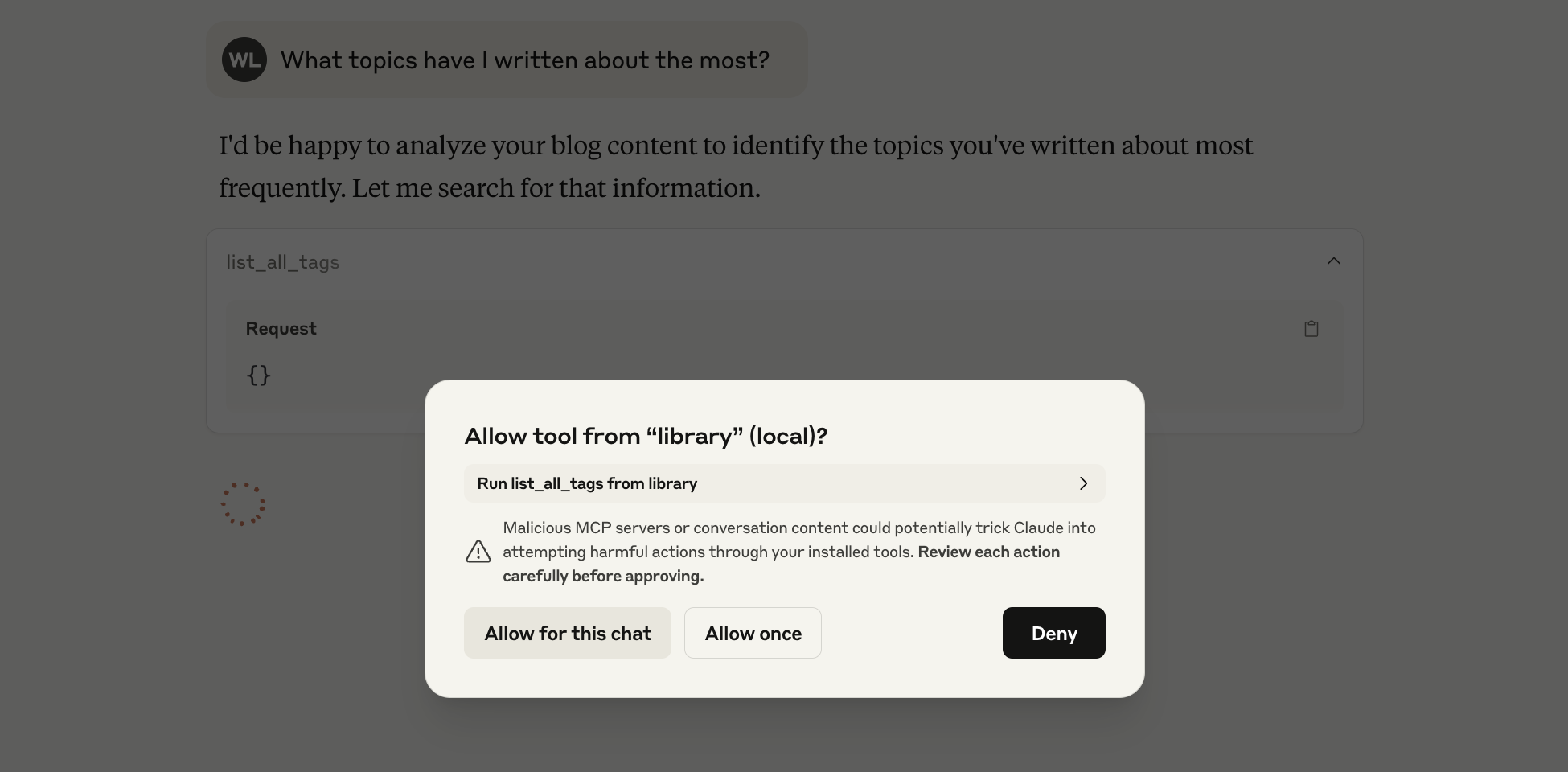
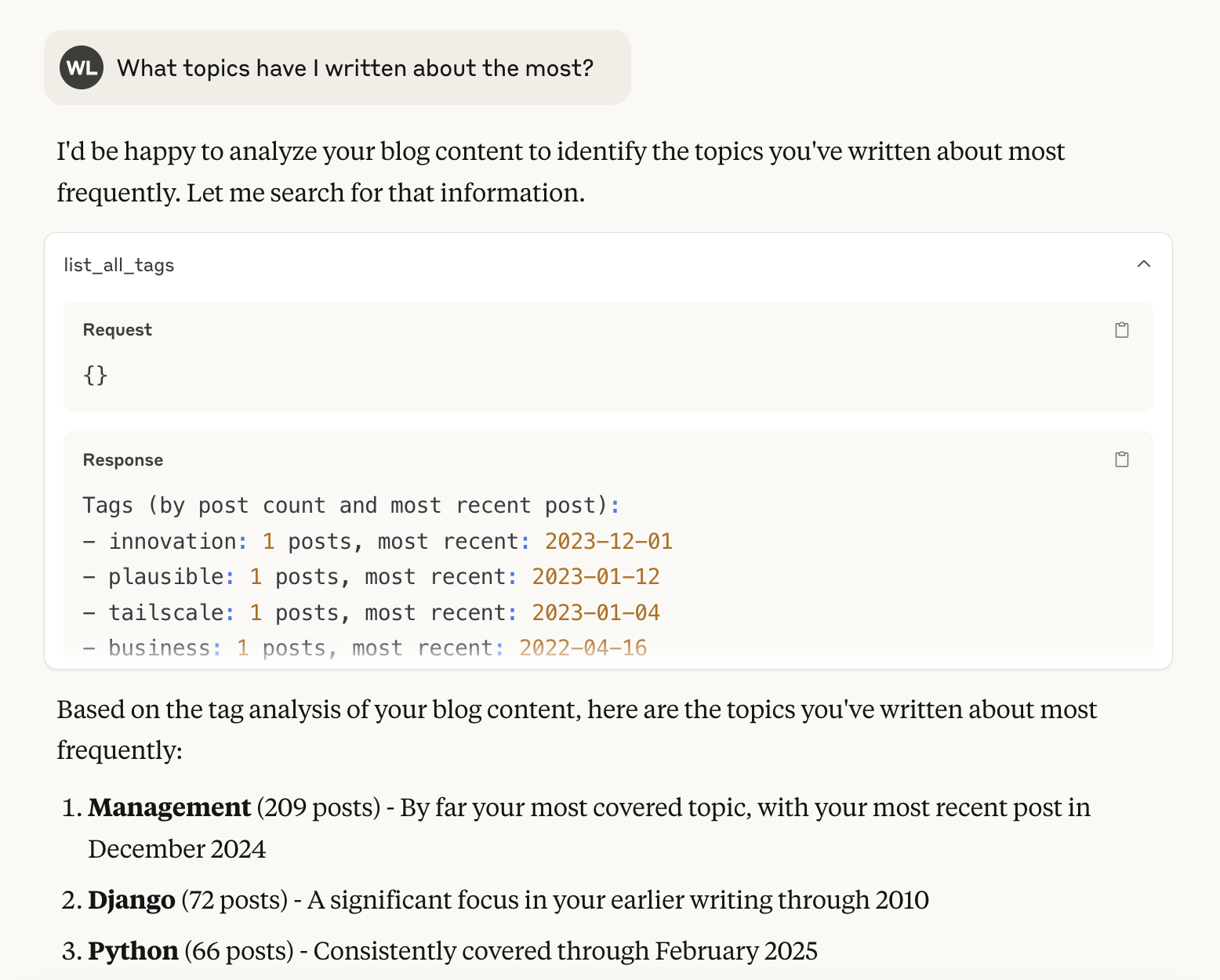
Here’s an example of retrieving all the tags to figure out what I’ve written about. You could do a follow-up like, “Get me posts I’ve written about ‘python’” after seeing the tags. The interesting thing here is you can combine retrieval and intelligence. For example, you could ask “Get me all the tags I’ve written, and find those that seem related to software architecture” and it does a good job of filtering.
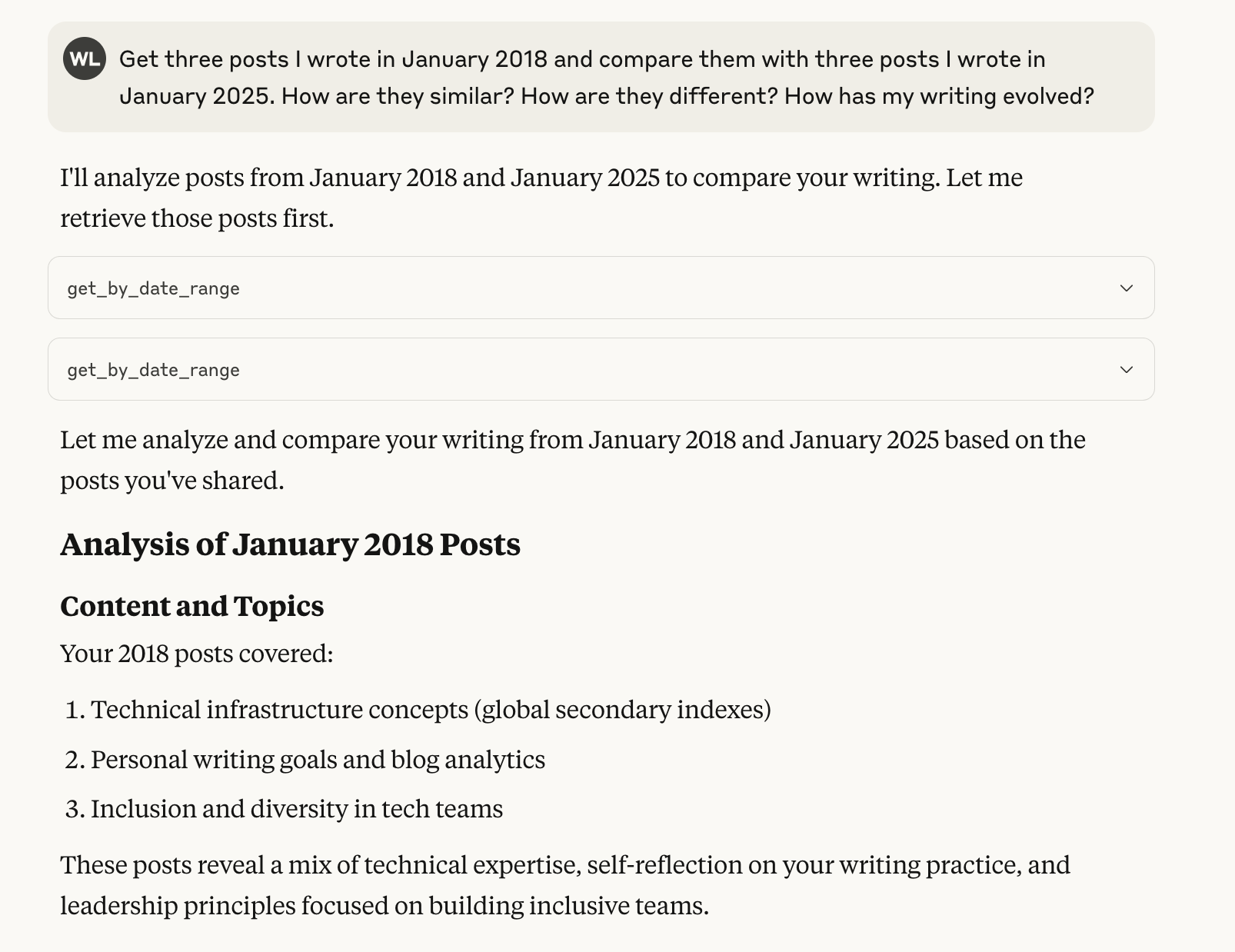
Finally, here’s an example of actually using a datapack to answer a question. In this case, it’s evaluating how my writing has changed between 2018 and 2025.
More practically, I’ve already experimented with friends writing their CTO onboarding plans with Your first 90 days as CTO as a datapack in the context window, and you can imagine the right datapacks allowing you to go much further. Writing a company policy with all the existing policies in a datapack, along with a document about how to write policies effectively, for example, would improve consistency and be likely to identify conflicting policies.
Altogether, I am currently enamored with the vision of useful datapacks facilitating
creation, and hope that library-mcp is a useful tool for folks as we experiment
our way towards this idea.
Refreshed StaffEng.com and a few other sites
Ahead of announcing the title and publisher of
my thus-far-untitled book on engineering strategy
in the next week or two, I put together a website for its content.
That site is pretty much the same format as this blog,
but with some improvements like better mobile rendering on / than this blog has historically had.
After finishing that work, I ported the improvements back to lethain.com, but also
decided to bring them to staffeng.com.
That was slightly trickier because, unlike this blog, StaffEng was historically a Gatsby app.
(Why a Gatsby app? Because Calm was using Gatsby for our web frontend and I wanted to get some experience with it.)
Over the weekend, I took some time to migrate to Hugo and apply the same enhancements.
which you can now see in the lethain:staff-eng
repository or on staffeng.com.
Here’s a screenshot of the old version.
Then here’s a screenshot of the updated version.
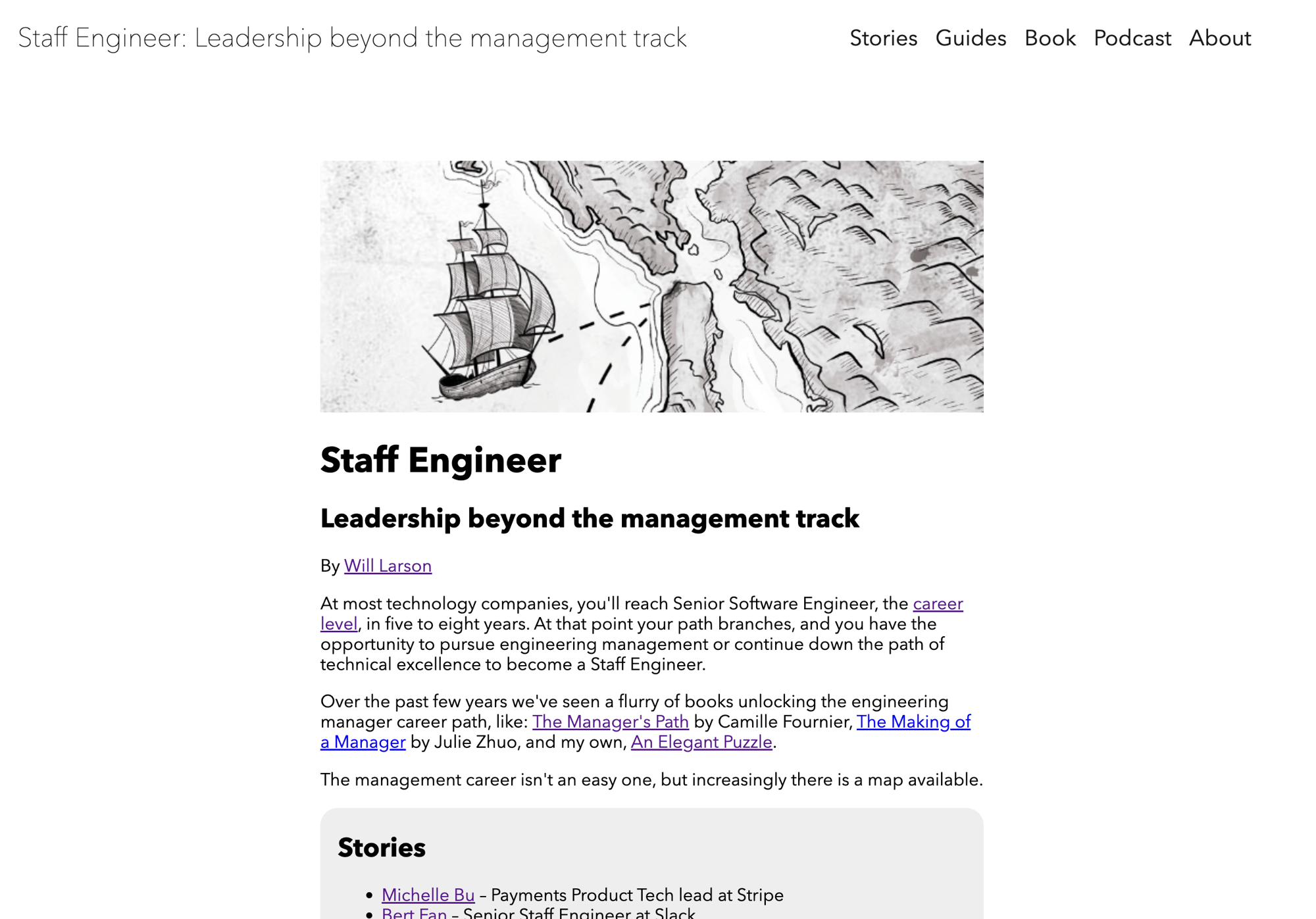
Overall, I think it’s slightly easier to read, and I took it as a chance to update the various links. For example, I removed the newsletter link and pointed that to this blog’s newsletter instead, given that one’s mailing list went quiet a long time ago.
Speaking of going quiet, I also brought these updates to infraeng.dev, which is the very-stuck-in-time site for the book I may-or-may-not one day write about infrastructure engineering. That means that I now have four essentially equivalent Hugo sites running different content websites: this blog, staffeng.com, infraeng.dev, and the site for the upcoming book. All of these build and deploy automatically onto GitHub Pages, which has been an extremely easy, reliable workflow for me.
While I was working on this, someone asked me why I don’t just write my own blog server to host my blogs. The answer here is pretty straightforward. I’ve written three blog servers for my blog over the years. The first two were in Python, and the last one was in Go. They all worked well enough, but maintaining them was eventually a pain point because they required a real build pipeline and deal with libraries that could have security issues. Even in the best case, the containers they run in would get end-of-lifed periodically as Ubuntu versions got deprecated.
What I’ve slowly learned from that is that, as a frequent writer, you really want your content to live somewhere that can work properly for decades. Even small maintenance costs can be prohibitive over time, and I’ve seen some good blogs disappear rather than e.g. figure out a WordPress upgrade. Individually, these are all minor, but over decades they can really add up. This is also my argument against using hosted providers: I’m sure Substack will be around in five years, but I have no idea if Substack will be around in twenty years, but I know that I’ll still be writing then, and will also want my previous writing to still be accessible.
Why did Stripe build Sorbet? (~2017).
Many hypergrowth companies of the 2010s battled increasing complexity in their codebase by decomposing their monoliths. Stripe was somewhat of an exception, largely delaying decomposition until it had grown beyond three thousand engineers and had accumulated a decade of development in its core Ruby monolith. Even now, significant portions of their product are maintained in the monolithic repository, and it’s safe to say this was only possible because of Sorbet’s impact.
Sorbet is a custom static type checker for Ruby that was initially designed and implemented by Stripe engineers on their Product Infrastructure team. Stripe’s Product Infrastructure had similar goals to other companies’ Developer Experience or Developer Productivity teams, but it focused on improving productivity through changes in the internal architecture of the codebase itself, rather than relying solely on external tooling or processes.
This strategy explains why Stripe chose to delay decomposition for so long, and how the Product Infrastructure team invested in developer productivity to deal with the challenges of a large Ruby codebase managed by a large software engineering team with low average tenure caused by rapid hiring.
Before wrapping this introduction, I want to explicitly acknowledge that this strategy was spearheaded by Stripe’s Product Infrastructure team, not by me. Although I ultimately became responsible for that team, I can’t take credit for this strategy’s thinking. Rather, I was initially skeptical, preferring an incremental migration to an existing strongly-typed programming language, either Java for library coverage or Golang for Stripe’s existing familiarity. Despite my initial doubts, the Sorbet project eventually won me over with its indisputable results.
This is an exploratory, draft chapter for a book on engineering strategy that I’m brainstorming in #eng-strategy-book. As such, some of the links go to other draft chapters, both published drafts and very early, unpublished drafts.
Reading this document
To apply this strategy, start at the top with Policy. To understand the thinking behind this strategy, read sections in reverse order, starting with Explore.
More detail on this structure in Making a readable Engineering Strategy document.
Policy & Operation
The Product Infrastructure team is investing in Stripe’s developer experience by:
-
Every six months, Product Infrastructure will select its three highest priority areas to focus, and invest a significant majority of its energy into those. We will provide minimal support for other areas.
We commit to refreshing our priorities every half after running the developer productivity survey. We will further share our results, and priorities, in each Quarterly Business Review.
-
Our three highest priority areas for this half are:
- Add static typing to the highest value portions of our Ruby codebase, such that we can run the type checker locally and on the test machines to identify errors more quickly.
- Support selective test execution such that engineers can quickly determine and run the most appropriate tests on their machine rather than delaying until tests run on the build server.
- Instrument test failures such that we have better data to prioritize future efforts.
-
Static typing is not a typical solution to developer productivity, so it requires some explanation when we say this is our highest priority area for investment. Doubly so when we acknowledge that it will take us 12-24 months of much of the team’s time to get our type checker to an effective place.
Our type checker, which we plan to name Sorbet, will allow us to continue developing within our existing Ruby codebase. It will further allow our product engineers to remain focused on developing new functionality rather than migrating existing functionality to new services or programming languages. Instead, our Product Infrastructure team will centrally absorb both the development of the type checker and the initial rollout to our codebase.
It’s possible for Product Infrastructure to take on both, despite its fixed size. We’ll rely on a hybrid approach of deep-dives to add typing to particularly complex areas, and scripts to rewrite our code’s Abstract Syntax Trees (AST) for less complex portions. In the relatively unlikely event that this approach fails, the cost to Stripe is of a small, known size: approximately six months of half the Product Infrastructure team, which is what we anticipate requiring to determine if this approach is viable.
Based on our knowledge of Facebook’s Hack project, we believe we can build a static type checker that runs locally and significantly faster than our test suite. It’s hard to make a precise guess now, but we think less than 30 seconds to type our entire codebase, despite it being quite large. This will allow for a highly productive local development experience, even if we are not able to speed up local testing. Even if we do speed up local testing, typing would help us eliminate one of the categories of errors that testing has been unable to eliminate, which is passing of unexpected types across code paths which have been tested for expected scenarios but not for entirely unexpected scenarios.
Once the type checker has been validated, we can incrementally prioritize adding typing to the highest value places across the codebase. We do not need to wholly type our codebase before we can start getting meaningful value.
-
In support of these static typing efforts, we will advocate for product engineers at Stripe to begin development using the Command Query Responsibility Segregation (CQRS) design pattern, which we believe will provide high-leverage interfaces for incrementally introducing static typing into our codebase.
-
Selective test execution will allow developers to quickly run appropriate tests locally. This will allow engineers to stay in a tight local development loop, speeding up development of high quality code.
Given that our codebase is not currently statically typed, inferring which tests to run is rather challenging. With our very high test coverage, and the fact that all tests will still be run before deployment to the production environment, we believe that we can rely on statistically inferring which tests are likely to fail when a given file is modified.
-
Instrumenting test failures is our third, and lowest priority, project for this half. Our focus this half is purely on annotating errors for which we have high conviction about their source, whether infrastructure or test issues.
-
For escalations and issues, reach out in the #product-infra channel.
Diagnose
In 2017, Stripe is a company of about 1,000 people, including 400 software engineers. We aim to grow our organization by about 70% year-over-year to meet increasing demand for a broader product portfolio and to scale our existing products and infrastructure to accommodate user growth. As our production stability has improved over the past several years, we have now turned our focus towards improving developer productivity.
Our current diagnosis of our developer productivity is:
-
We primarily fund developer productivity for our Ruby-authoring software engineers via our Product Infrastructure team. The Ruby-focused portion of that team has about ten engineers on it today, and is unlikely to significantly grow in the future. (If we do expand, we are likely to staff non-Ruby ecosystems like Scala or Golang.)
-
We have two primary mechanisms for understanding our engineer’s developer experience. The first is standard productivity metrics around deploy time, deploy stability, test coverage, test time, test flakiness, and so on. The second is a twice annual developer productivity survey.
-
Looking at our productivity metrics, our test coverage remains extremely high, with coverage above 99% of lines, and tests are quite slow to run locally. They run quickly in our infrastructure because they are multiplexed across a large fleet of test runners.
-
Tests have become slow enough to run locally that an increasing number of developers run an overly narrow subset of tests, or entirely skip running tests until after pushing their changes. They instead rely on our test servers to run against their pull request’s branch, which works well enough, but significantly slows down developer iteration time because the merge, build, and test cycle takes twenty to thirty minutes to complete.
By the time their build-test cycle completes, they’ve lost their focus and maybe take several hours to return to addressing the results.
-
There is significant disagreement about whether tests are becoming flakier due to test infrastructure issues, or due to quality issues of the tests themselves. At this point, there is no trustworthy dataset that allows us to attribute between those two causes.
-
Feedback from the twice annual developer productivity survey supports the above diagnosis, and adds some additional nuance. Most concerning, although long-tenured Stripe engineers find themselves highly productive in our codebase, we increasingly hear in the survey that newly hired engineers with long tenures at other companies find themselves unproductive in our codebase. Specifically, they find it very difficult to determine how to safely make changes in our codebase.
-
Our product codebase is entirely implemented in a single Ruby monolith. There is one narrow exception, a Golang service handling payment tokenization, which we consider out of scope for two reasons. First, it is kept intentionally narrow in order to absorb our SOC1 compliance obligations. Second, developers in that environment have not raised concerns about their productivity.
Our data infrastructure is implemented in Scala. While these developers have concerns–primarily slow build times–they manage their build and deployment infrastructure independently, and the group remains relatively small.
-
Ruby is not a highly performant programming language, but we’ve found it sufficiently efficient for our needs. Similarly, other languages are more cost-efficient from a compute resources perspective, but a significant majority of our spend is on real-time storage and batch computation. For these reasons alone, we would not consider replacing Ruby as our core programming language.
-
Our Product Infrastructure team is about ten engineers, supporting about 250 product engineers. We anticipate this group growing modestly over time, but certainly sublinearly to the overall growth of product engineers.
-
Developers working in Golang and Scala routinely ask for more centralized support, but it’s challenging to prioritize those requests as we’re forced to consider the return on improving the experience for 240 product engineers working in Ruby vs 10 in Golang or 40 data engineers in Scala.
If we introduced more programming languages, this prioritization problem would become increasingly difficult, and we are already failing to support additional languages.
That's all for now! Hope to hear your thoughts on Twitter at @lethain!
|